Organizations want to bring Machine Learning capabilities into their core software products/offerings to monetize data assets. C-Suite leaders are looking for AI Solutions that can provide them with a clear understanding of return on investment, a challenge in many data science projects. By putting MLOps (Machine learning Operations) in place, leaders can utilize their energy into scaling AI capabilities across the organization while focusing on tracking KPIs (Key Performance Indicators) that matter to teams and departments which in turn will help them to highlight ROI on AI investments.
Executing Machine Learning projects is complex and significantly different from building regular software. Machine Learning projects are more experimental and iterative in nature and requires a different setup and skillset as compared to standard software development. The typical steps involved in Machine Learning projects are:
- Requirements gathering
- Exploratory data analysis
- Feature engineering
- Feature selection
- Model creation
- Model hyperparameter tuning
- Model deployment
- Model monitoring
- Retraining (if needed)
Each of these steps requires a culmination of different skills like Data Engineering, Data Science, and DevOps to meet the ends. After a successful deployment of the model into production it may generate results that are different from those observed during development. One might also need to revisit any or all the prior steps to correct the model and behave as per expectation. Because of this iterative and experimental nature of Machine Learning Projects one needs a strong ML pipeline framework in place that will help ML teams to quickly experiment and roll out models into production in less time, ML team must establish a set of best practices that will help them to build, deploy, maintain, and monitor Machine learning models in production effectively and efficiently.
The levels of automation of above steps define the maturity of ML pipeline. Below are some ML pipeline configurations at different maturity levels.
Level 0:
Many teams have data scientists and Machine learning engineers who can build state of the art of models, but their process for building and deploying models is entirely manual. This is considered the basic level of maturity or Level 0. The following diagram shows the workflow of the process.
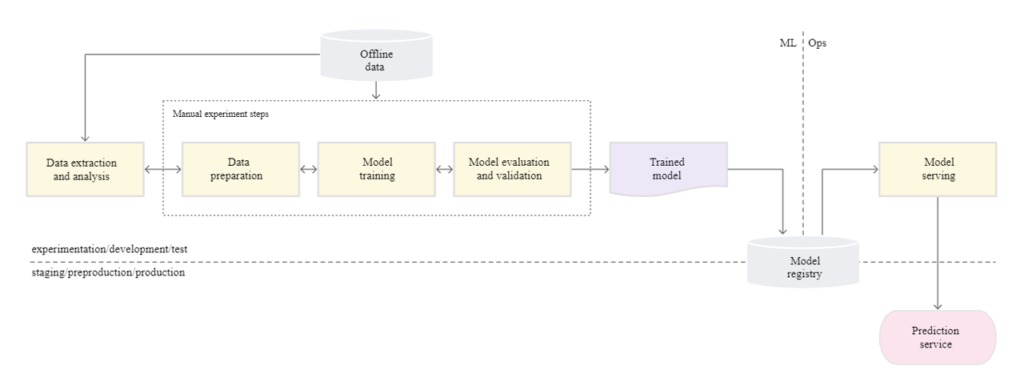
Characteristics:
- Every step of the ML pipeline is manual, starting from data analysis to model validation, usually driven by experimental code written in notebooks by data scientists
.
- Data Scientists handover the trained model to the engineering team for deployment, handoff can include copying trained model in blob storage, check into code repos, or upload into a model registry
- Testing the code is done manually by Data Scientists in their python notebooks and CI/CD is ignored.
- Deployment process is concerned only with deploying the trained model as API or batch job, rather than considering the entire ML pipeline.
- Lack of active performance tracking.
- This setup is suitable for ML teams who are just starting to apply ML into their software and where models are rarely changed or trained.
- This setup fails to adapt to changes in the dynamics of the environment or changes in the data that describes the environment.
One must adopt Level – 1 to automate ML pipeline for continuous training and continuous delivery of prediction services
Level 1:
The objective of Level 1 is to automate the pipeline components to consume the new data for continuous training and in turn continuously deliver prediction services. The following diagram shows the workflow of Level 1 process.
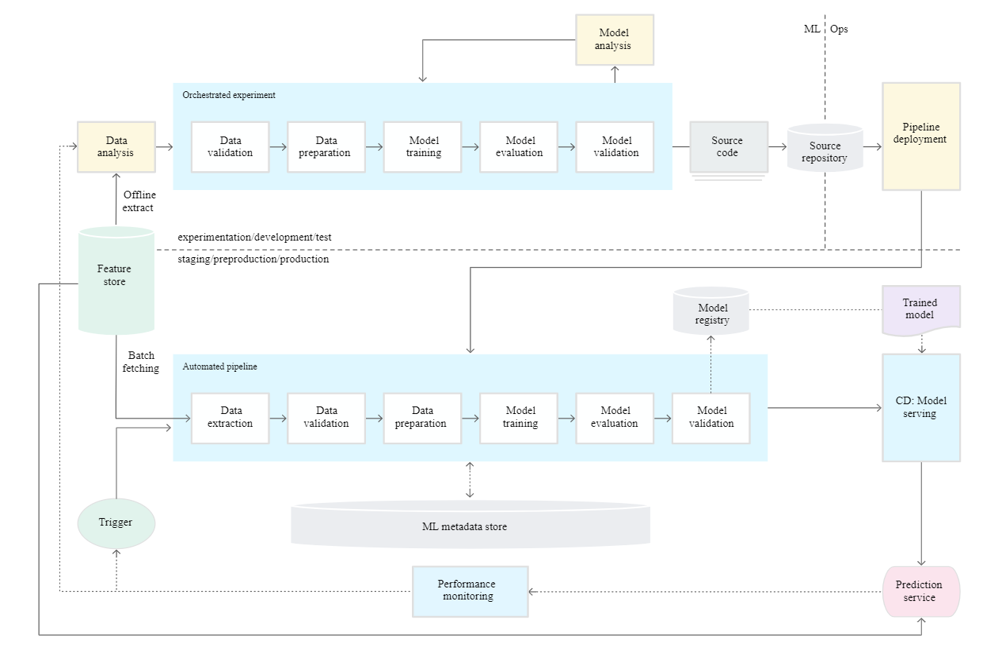
Characteristics:
- All the steps of the ML pipeline are orchestrated and the transition between them is automated, this will allow for rapid iterations of experiments and better readiness to move the system into production
.
- Model is automatically trained in production using fresh data based on live pipeline triggers
- There is an operational symmetry between experimental and production phases since same code implementations are used in both the environments
.
- Training-Serving Skew can be avoided since in both phases model features are picked from the up-to-date feature store.
- Since code is modularized for components and pipeline each module can be easily containerized and can be executed separately in different target execution environments.
- Unlike level 0, deployment considers the whole training pipeline instead of just model deployment
.
- ML pipeline continuously delivers prediction services to new models that are trained on new data.
- This setup still tests and deploys pipelines and components manually.
- This setup is suitable for the automatic deployment of new models into production based on new data rather than based on new ML Ideas and component implementations
- One has to set up below four modules to achieve level -1 maturity
- Data and Model validation
- Feature Store
- Metadata Management
- ML pipeline Triggers
Level 2:
Level 2 maturity is Level 1 + CI/CD integrated into the system, this automated CI/CD system will allow Data Scientists to rapidly explore new ideas around feature engineering, Model architecture, and Hyperparameters, they can implement new ideas and automatically build, test, and deploy new pipeline components to the target environment.
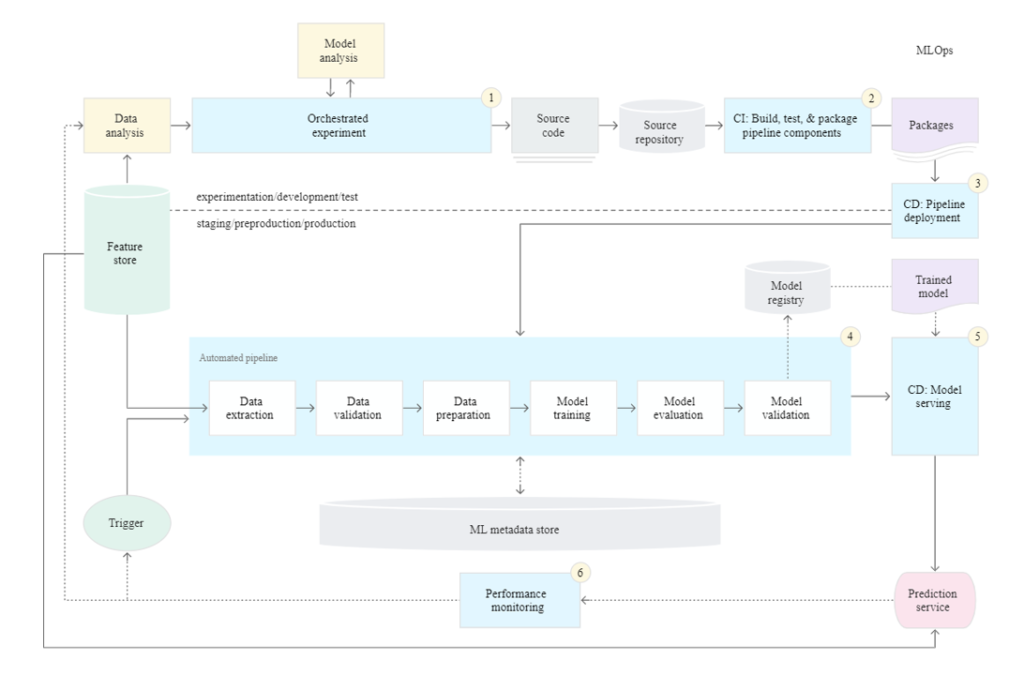
Characteristics:
- Continuously integrate the ML Pipeline code into the source code repository
.
- Unit test cases for various pipeline components like feature engineering, model testing, model training convergence and integration testing between pipeline components will be automatically executed
.
- Automated Triggering process to execute the pipeline and push the trained model into the model registry
.
- continuous model monitoring for data drifts, which in turn can act as a trigger to start the execution of pipeline.
- continuous delivery of trained models
To summarize implementing ML in production environment does not mean just deploying the models as APIs but implementing end to end pipeline which can automate retraining and deployment of models. Integrating CI/CD into the process will enable ML teams to automate and quickly test and deploy new pipeline implementations into production. One must gradually move from Level 0 to Level 2 to automate the entire ML pipeline process and be ready to adopt every changing dynamic of the domain.
If your ML team is experiencing bottlenecks, taking a longer time to move models from experimental phase to production, experiences errors and you are considering revisiting your ML pipeline architecture, our expertise will help you to solve your problem. Please reach out to us at connect@ngenux.com for some exciting perspectives and support.